Что такое PDF-файл?
PDF-файлы встречаются повсюду. От технических руководств и юридических договоров до маркетинговых брошюр и программной документации — переводчики регулярно получают проекты в формате PDF. Однако любой, кто работал с PDF, знает: их конвертация в редактируемый, пригодный для перевода контент может оказаться неожиданно сложной задачей.
Формат переносимых документов (PDF) был разработан компанией Adobe в 1990-х годах для сохранения форматирования документов в разных системах. В отличие от файлов Word или HTML, PDF предназначены прежде всего для визуального представления, а не для редактирования. PDF-файл хранит: текстовые элементы, шрифты и глифы, векторную графику, изображения, координаты макета и встроенные метаданные.
Ключевой момент: PDF-файлы — это постраничные визуальные документы, а не структурированные текстовые. Иными словами, PDF сообщает компьютеру, как должна выглядеть страница, но не обязательно какова логическая структура текста. Именно поэтому конвертация PDF в редактируемый текст столь трудоёмка.
Почему конвертация PDF так сложна
При попытке конвертировать PDF в редактируемые форматы, например Word, нередко возникает сразу несколько проблем.
1. Отсутствие логической структуры
В отличие от документов Word, PDF не всегда содержат чёткую информацию об абзацах, заголовках или порядке чтения. Абзац из трёх строк может храниться внутри документа в виде отдельных позиционированных текстовых блоков, что существенно затрудняет восстановление исходного абзаца.
2. Проблемы с многоколончатым форматом
Многие PDF используют многоколончатые макеты — особенно брошюры, технические руководства или научные статьи. Инструменты конвертации вынуждены угадывать правильный порядок чтения. Результат выглядит примерно так: строка 1 столбца 1 / строка 1 столбца 2 / строка 2 столбца 1 / строка 2 столбца 2. Это делает правильный перевод без ручной правки практически невозможным.
3. Встроенные шрифты и символы
Некоторые PDF используют встроенные шрифты или нестандартные глифы — формы символов сохраняются как графические элементы, а не настоящий текст. При конвертации такие символы могут превращаться в неверные буквы, пропадать или отображаться как странные знаки.
4. Отсканированные PDF
Многие PDF — просто отсканированные изображения документов, не содержащие никакого текста, только картинки. Для извлечения текста система должна использовать оптическое распознавание символов (OCR), что неизбежно вносит дополнительные ошибки.
Почему переводчики часто получают PDF
Несмотря на все ограничения, PDF по-прежнему крайне распространены в переводческих проектах. Клиенты предпочитают PDF, поскольку они сохраняют исходный макет, исключают случайное редактирование, удобны для хранения и передачи и выглядят одинаково на любых устройствах. Однако эта удобство для заказчика, как правило, означает дополнительную работу для переводчика.
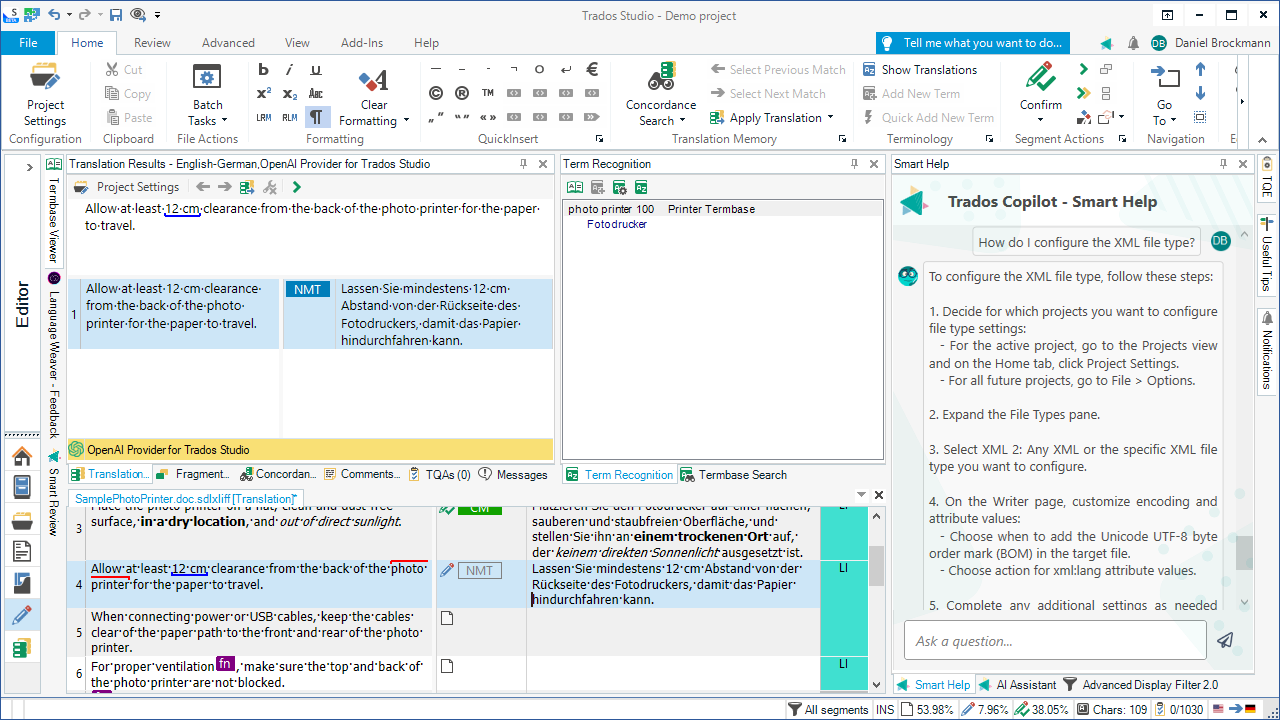
Как SDL Trados Studio конвертирует PDF-файлы
Профессиональные CAT-инструменты, такие как SDL Trados Studio, включают встроенные механизмы обработки PDF. Типичный рабочий процесс выглядит так:
- Импортировать PDF в SDL Trados Studio
- Система пытается извлечь текст из документа
- Извлечённый контент конвертируется в SDLXLIFF-файл
- Переводчик работает с SDLXLIFF-файлом в редакторе Trados
Формат SDLXLIFF — двуязычный формат перевода, содержащий исходные сегменты, целевые сегменты и теги с метаданными форматирования. Однако качество SDLXLIFF-файла целиком зависит от того, насколько хорошо удалось разобрать исходный PDF.
Типичные проблемы после импорта PDF в SDL Trados
Даже при работе в SDL Trados переводчики могут столкнуться с рядом проблем после импорта PDF:
- Ошибки сегментации: предложения могут быть разделены неверно, образуя неудобные переводческие единицы.
- Отсутствующий текст: некоторые текстовые блоки могут не распознаваться при конвертации.
- Теги форматирования: сложные макеты нередко порождают множество тегов, замедляющих работу.
- Переупорядоченный контент: абзацы могут следовать не в том порядке, особенно в документах с несколькими столбцами.
Эти проблемы могут существенно увеличить время подготовки проекта.
Почему полезно просматривать конвертированные файлы вне CAT-инструментов
Переводчикам часто требуется проверить извлечённый контент вне CAT-инструмента. Работа с файлами в Word или Excel позволяет изучить структуру извлечённого текста, выявить проблемы с сегментацией, проанализировать использование терминологии, провести контроль качества и поделиться файлами с рецензентами или заказчиками. Это особенно ценно при работе с объёмными документами или сложными макетами.
Конвертация PDF-файлов с помощью конвертера Linigu
PDF Converter на linigu.cloud помогает переводчикам упростить работу с PDF-документами. Вместо ручного извлечения текста или борьбы с проблемами форматирования конвертер позволяет преобразовать содержимое PDF в чистые, удобочитаемые форматы, которые легче анализировать и обрабатывать.
С его помощью переводчики могут конвертировать PDF в структурированные данные, просматривать текст вне исходной среды PDF, готовить документы для переводческих рабочих процессов и быстро проверять извлечённый контент. Такой подход способен значительно сократить время подготовки до начала перевода.
Лучшие практики для переводчиков, работающих с PDF
Запросить исходный файл
По возможности просите клиентов предоставить оригинальный исходный файл (Word, InDesign и т. д.) вместо PDF.
Сначала проверить извлечение
Всегда просматривайте извлечённый текст перед началом перевода.
Очистить документ
Удалите ошибки форматирования, лишние переносы строк и дублирующиеся сегменты.
Использовать инструменты конвертации
Инструменты вроде PDF Converter на linigu.cloud ускоряют подготовку документов и уменьшают ручной труд.
Будущее конвертации PDF в переводе
Технологии распознавания документов на основе ИИ стремительно повышают точность конвертации PDF. Современные системы способны определять структуру текста, макеты таблиц, иерархию документа и порядок чтения. По мере развития этих технологий переводчики будут всё активнее использовать интеллектуальные инструменты конвертации документов для подготовки файлов перед переводом. Эффективная предобработка документов становится неотъемлемой частью профессионального переводческого процесса.
Заключение
PDF-файлы — один из наиболее распространённых и наиболее сложных форматов, с которыми сталкиваются переводчики. Поскольку они создаются для визуального представления, а не редактируемой структуры, их конвертация в контент, готовый к переводу, может порождать ошибки, проблемы форматирования и неверную сегментацию. Инструменты вроде SDL Trados Studio пытаются конвертировать PDF в SDLXLIFF-файлы для перевода, однако качество во многом определяется структурой исходного документа. Специализированные инструменты — в частности PDF Converter на linigu.cloud — помогают переводчикам эффективнее проверять и конвертировать PDF-файлы, облегчая подготовку документов и контроль качества.